+++primary 什么是爬虫?
爬虫是一种自动化程序,它按照一定的规则来爬取互联网上的各种有用的信息,为自己所用。
爬取信息前务必遵守网站的robots协议,遵守网站服务条款,严禁爬取网站用户个人信息!!
爬虫的基本流程
·发送请求
·解析网页
·提取数据
·存储数据
+++
先来一些简单的小例子!
;;;id1 豆瓣排行榜
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import requests
from bs4 import BeautifulSoup
url = "http://movie.douban.com/top250"
hearders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
reponse = requests.get(url, headers=hearders)
soup = BeautifulSoup(reponse.text, "html.parser")
moive_titles = soup.find_all('span', class_='title')
with open('douban.txt', 'w', encoding="utf-8") as e:
for title in moive_titles:
print(title.text)
e.write(title.text + '\n')
|
;;;
;;;id1 知乎热榜
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import requests
from bs4 import BeautifulSoup
url = "https://www.zhihu.com/billboard"
hearders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
reponse = requests.get(url, headers=hearders)
soup = BeautifulSoup(reponse.text, "html.parser")
moive_titles = soup.find_all('div', class_='HotList-itemTitle')
with open('zhihu.txt', 'w', encoding="utf-8") as e:
for title in moive_titles:
print(title.text)
e.write(title.text + '\n')
|
;;;
;;;id1 微博热榜
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import requests
from bs4 import BeautifulSoup
url = "https://www.trendshub.today/medias/weibo"
hearders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
reponse = requests.get(url, headers=hearders)
print("网页状态码:", reponse.status_code)
soup = BeautifulSoup(reponse.text, "html.parser")
moive_titles = soup.find_all('div', class_='flex')
with open('weibo.txt', 'w', encoding="utf-8") as e:
for title in moive_titles:
print(title.text)
e.write(title.text + '\n')
|
;;;
在以上三个例子中,可以作为简单的爬取简单元素的模板,每一条代码都进行了详细的解释,唯一有疑问的应该是[moive_titles = soup.find_all()]{.label},这里面的参数是如何来的呢?
接下来就需要你使用浏览器开发者工具分析网页结构,引号里面的是某个网页元素结构的[标签]{.label .primary},而class_的值为网页元素的[属性]{.label .primary}(可能有小伙伴会有疑问,为什么使用class_而不是class,这是为了与python本身的类关键词class区分)
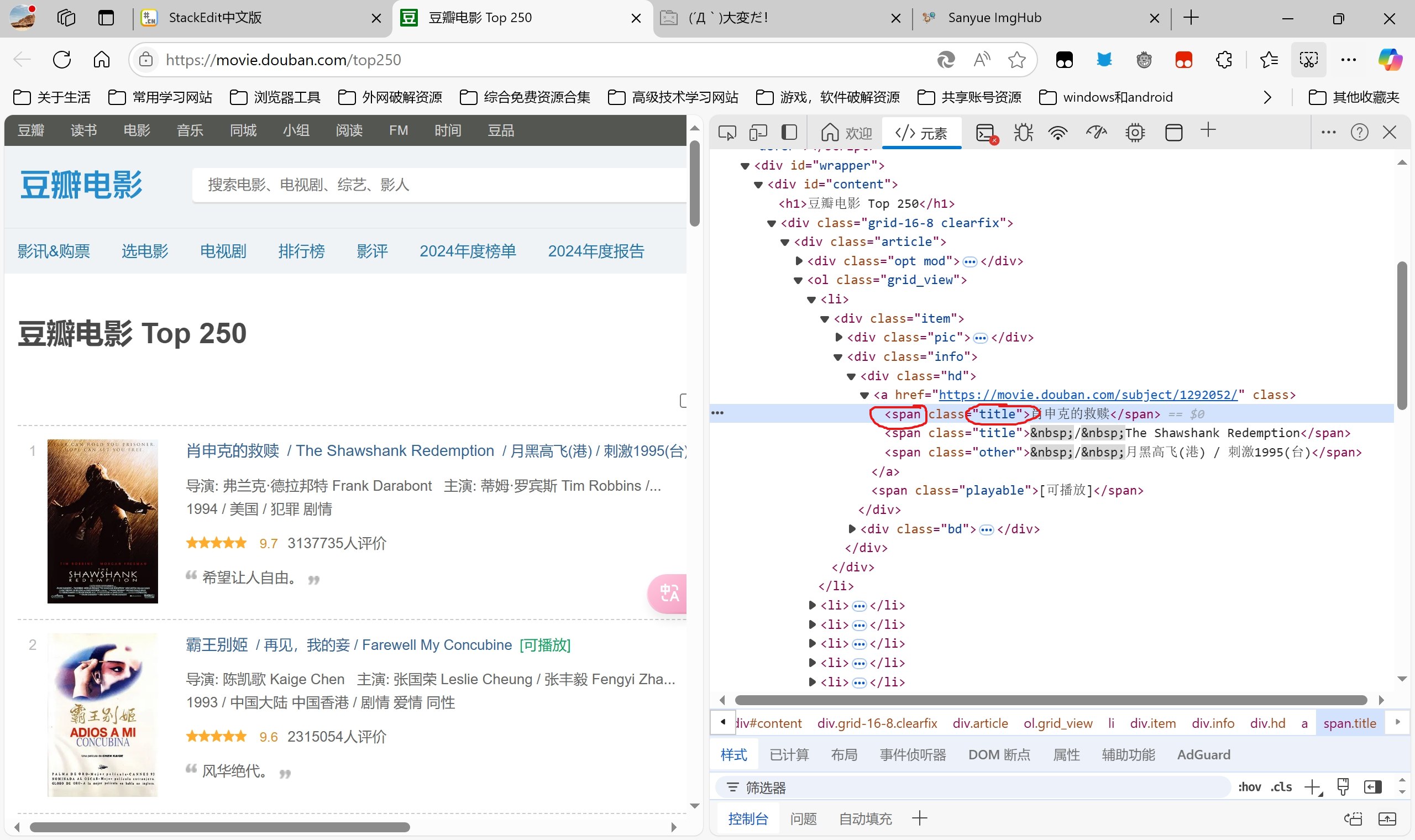
如何寻找呢?
首先我们来观察豆瓣排行榜网页结构,鼠标放在标题上方,右键选择“检查”或者“审查元素”,可快速定位位置

我们可以观察到排行榜的每一个标题元素的标签都是span,属性class都是title,所以获取网页标题的主代码就是[moive_titles = soup.find_all(‘span’, class_ = ‘title’)]{.label}。
剩下的例子都是相同的道理,当然了,这只是最基础的,有时候我们会碰到更复杂的网页结构,后面我们会细讲。